Can I Change Binance to Read in Usd Only
Last Updated on Nov 3, 2020
Table of Contents
- What is yfinance?
- Is the yfinance library complimentary?
- Why should I use the yfinance library?
- Why shouldn't I use the yfinance library?
- What are some of the alternatives to the yfinance library?
- RapidAPI
- yahoo_fin
- How exercise I get started with the yfinance library?
- Installation
- Library Layout
- How do I download historical data using the yfinance library?
- Demo with ane ticker
- Demo with multiple tickers
- How practise I download fundamental data using the yfinance library?
- Price to Earnings Ratio
- Dividends
- Fundamentals data with multiple tickers at one time
- Comparing by a particular attribute
- How do I download trading data using the yfinance library?
- Market Cap
- Book
- Highs and Lows
- How do I download options data using the yfinance library?
- How do I get Expiration dates?
- How do I get Calls Information?
- How do I go Puts Data?
- Common errors
- Terminal thoughts
- Link to download lawmaking used
What is yfinance?
yfinance is a pop open source library adult by Ran Aroussi every bit a means to admission the financial data available on Yahoo Finance.
Yahoo Finance offers an excellent range of market data on stocks, bonds, currencies and cryptocurrencies. Information technology also offers market place news, reports and analysis and additionally options and fundamentals information- setting information technology apart from some of it's competitors.
Yahoo Finance used to take their ain official API, just this was decommissioned on May 15th 2017, post-obit wide-spread misuse of information.
These days a range of unofficial APIs and libraries exist to access the same data, including of form yfinance.
Notation y'all might know of yfinance under it's old proper name- gear up-yahoo-finance, since it was re-named on May 26th 2019 at the aforementioned time that it went over a large overhaul to fix some usability issues.
To ensure backwards compatibility, set up-yahoo-finance now imports and uses yfinance anyway, but Ran Aroussi however recommends to install and use yfinance directly.
In this article we will focus mainly on the yfinance library, but we hash out the overall range of options and other alternative providers in more depth in our parent article, Yahoo Finance API – A Consummate Guide.
Is the yfinance library free?
Yeah, yfinance is completely open up source and free. You tin can find the documentation here.
Why should I use the yfinance library?
- Free
- Quick and easy to set up yourself up
- Unproblematic
- High granularity of data (1min/2min/5min data)
- Returns data straight in pandas dataframes/serial
Every bit nosotros have simply mentioned yfinance is completely open source and gratis. There are other ways to admission the Yahoo Finance data, some free and some paid, and in that location are certain benefits to some of the options that require paying, like being ensured a degree of maintenance to the solution, but everybody loves gratis!
Installation couldn't be quicker or easier. yfinance has only 4 dependencies, all of which come with Anaconda anyway, and installs fully in a single line of code. No account cosmos required, or signing upwards for and using API keys!
Its elementary. yfinance is highly Pythonic in it's design and incredibly streamlined. Information technology's as easy as creating a ticker object for a particular ticker/list of tickers and then but calling all the methods on this object. Similar this:
import yfinance every bit yf apple= yf.Ticker("aapl") # show deportment (dividends, splits) apple.deportment # prove dividends apple.dividends # testify splits apple.splits # + other methods etc. Don't worry, nosotros'll suspension down that code further in a bit!
Furthermore, the documentation is curtailed- plumbing fixtures on a single page, and the method names are very self explanatory.
High granularity of information. One absurd characteristic of yfinance is that you can get highly refined data, all the way down to 5 minute, iii infinitesimal and even ane minute data! The full range of intervals available are:
1m, 2m, 5m, 15m, 30m, 60m, 90m, 1h, 1d, 5d, 1wk, 1mo, 3mo However it is important to note that the 1m data is only retrievable for the last 7 days, and anything intraday (interval <1d) simply for the terminal lx days.
yfinance as well handily returns data directly in padas dataframes or serial. This is on contrast to some other options to access Yahoo Finance's information where yous volition go lengthy JSONs you lot need parse for the specific information y'all want, and will have to manually convert to data-frames yourself.
Why shouldn't I use the yfinance library?
- Lacks specialised features
- Some methods are fragile
- Unofficial / not necessarily maintained
- Can get yourself rate limited/blacklisted
Lacks specialised features. Despite the fact you can utilise information technology to go a expert range of core information, including options and fundamentals data, yfinance doesn't provide a method to scrape any of the news reports/analysis that are bachelor on Yahoo Finance.
This obviously isn't platonic if you want to build model that relies in part on sentiment analysis, so if you desire that sort of data, you might desire to check out RapidAPI (which will talk about more shortly) that does offer such data.
As well, other market data alternatives oftentimes include interesting extras. For case Alpha Vantage provides modules that calculate various technical analysis indicators for y'all- obviously an enormous effort save if y'all want to build an algorithm utilising whatsoever of them! yfinance just provides the nuts.
Some methods are fragile. yfinance mainly makes API calls to Yahoo Finance to gather it's information, but it does occasionally employ HTML scraping and pandas tables scraping to unofficially assemble the information off the Yahoo Finance website for some of information technology's methods. As such, the functionality of some of it's methods is at the mercy of Yahoo not changing the layout or design of some of their pages. In fact, yfinance is widely known to already take a few issues.
As a quick bated, data scraping works by just downloading the HTML code of a web page, and searching through all the HTML tags to detect the specific elements of a page you want.
For case below is the Yahoo Finance Apple ('AAPL') historical information page:

If the method to get the historical data HTML scraped, it would be searching the various div, grade and tr tags etc. for various IDs to selection out the data that should be returned.
For case the class ID "Py(10px) Pstart(10px)" refers to the historical prices populating the table. If in this example Yahoo Finance was to change the class ID pointing to this value, the method might return completely incorrect data, or even cipher at all. Once again, this sort of vulnerability doesn't apply to all of yfinance's methods- most of them practise in fact brand direct API calls- only it does touch on a few.
Information technology'southward an unofficial solution. Again, because yfinance is simply the result of ane man's hard work and non in whatsoever way affiliated with Yahoo Finance, there's no guarantee if it breaks it volition be maintained.
As we already mentioned it did have a large update to set issues on May 26th 2019 on the same day information technology was renamed, only that'south no guarantee problems will exist fixed in the futurity. Are you sure yous desire to build a trading algorithm on-top of data that might one twenty-four hours suddenly and without warning be wrong? There are already a few known problems with yfinance, which we will highlight afterwards on in this article.
You tin can get yourself rate limited/blacklisted. Once again because yfinance scrapes information for a few of information technology's functions, you sometimes run the risk of getting charge per unit limited or blacklisted for besides many scraping attempts.
This is a risk that'southward always present when trying to scrape websites, simply when you're edifice applications trading real money on-top of infrastructure that might be making a lot of data requests, the risk:advantage changes.
Determination
Overall yfinance an incredibly beginner friendly option. You'll be able to dive right in and test out ideas without wasting fourth dimension puzzling over complex documentation whilst nevertheless having access to a good range of information!
That said, the risk of getting faulty data or beingness blocked from getting any data at all when employing algorithms trading existent money is absolutely unacceptable.
We think yfinance is great for prototyping, or if you are beginner, or just want to download a bunch of celebrated data.
Merely if you want complete confidence that a serious trading arrangement is going to function with full reliability, we'd absolutely recommend going with a official and culling market information provider- preferably one claiming to provide depression latency data straight from exchanges.
Polygon and IEX might make adept bets.
What are some of the alternatives to the yfinance library?
RapidAPI
Of the two alternatives to yfinance we will consider, RapidAPI is the about distinct.
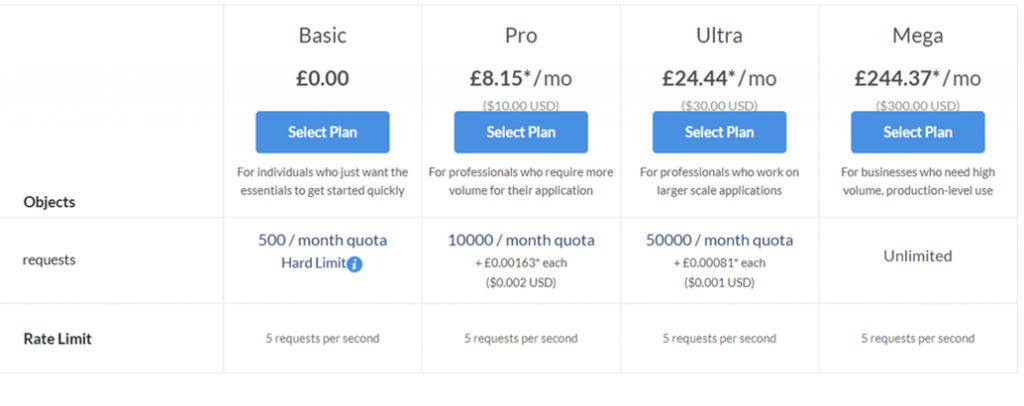
Firstly, whilst it does still have a limited usage gratuitous tier, y'all will have to pay for anything over 500 requests per month:
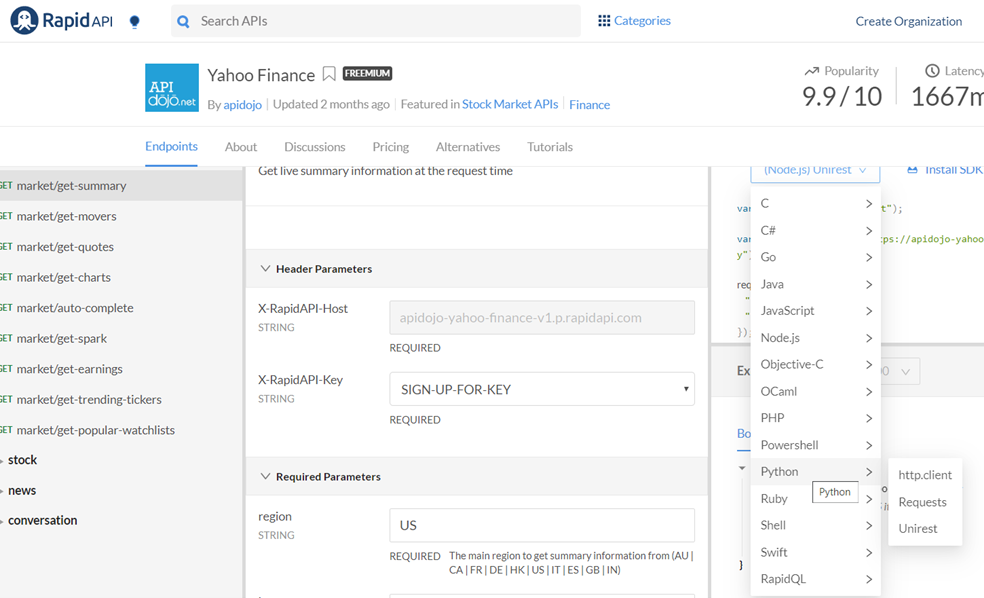
Secondly, its not quite equally simple equally yfinance to get started with. You lot will have to sign up for an business relationship to get your own access API keys.
That said, a big plus of RapidAPI is that you tin employ it with 15 different languages, if for some reason Python isn't your affair:
Information technology also offers more than range of data than our other options, specifically the option to download market news and analysis which is fantastically useful if you desire to add together a caste of sentiment analysis in your model!
Making snap trading decisions based on car scanning of news far faster than a man ever could can exist one style (if slightly uncertain) to gain a trading edge.
That said RapidAPI does accept a few drawbacks.
Every bit you can see requests have an average latency of 1660ms which isn't terrible, but culling data providers such every bit polygon.io offer annihilation from 200ms downward to 1ms delays- quite the difference.
More concerning is the fact requests just have a 98% success charge per unit. Having ane in fifty data requests fail could be a big bargain if you have a organisation trading real money, especially if you are making a lower frequency of calls. Definitely something to consider.

Results returned can also be in quite lengthy and nested JSONs, making the data a bit trickier to become ready for use than when using yfinance:
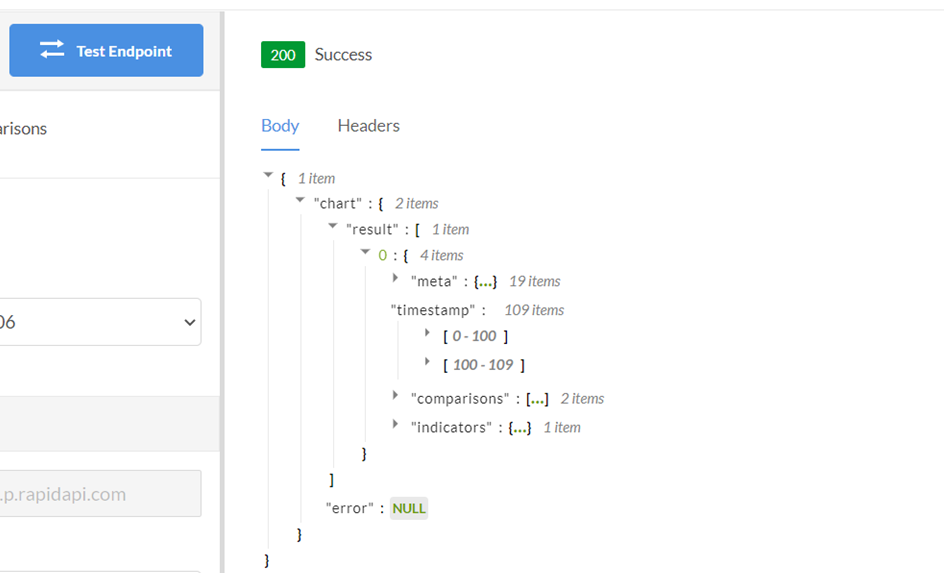
That said a further plus of RapidAPI is that it offers a huge range of APIs for other purposes, so familiarising yourself with how to utilize the their API for Yahoo Finance data might carry over into hands using some other of their APIs for a unlike project in the future.
In summary, RapidAPI offers a very limited free tier, merely maybe by using a solution where some people are paying, it is more than probable that any scraping problems from Yahoo Finance construction changes are resolved more rapidly.
Its also fiddlier to use and harder get started with, but does provide a bigger range of information than our other two options.
yahoo_fin
yahoo_fin is an open source and free library like to yfinance.
You can find the documentation here.
Information technology offers a like range of data to yfinance, but notably has a few functions that generate all the tickers for certain markets for you:
- tickers_dow()
- tickers_nasaq()
- tickers_other()
- tickers_sp500()
which is a useful feature yfinance lacks.
Nosotros really focus on the yahoo_fin library in the example sections of our parent article, Yahoo Finance API – A Consummate Guide, so we won't talk about it anymore here.
How exercise I go started with the yfinance library?
Installation
Getting started with the yfinance library is super easy.
It has the post-obit dependencies:
- pandas >= 0.24
- numpy >= 1.15
- requests >= 2.21
- multitasking >= 0.0.7
These all come as standard in an installation with Anaconda, but are really easy to install manually if for some reason you don't accept them.
Afterwards that its as easy as:
$ pip install yfinance --upgrade --no-enshroud-dir or
$ conda install -c ranaroussi yfinance to install yfinance.
Library Layout
The layout itself is also really uncomplicated, there are simply 3 modules:
- yf.Tickers
- yf.download
- yf.pandas_datareader
Virtually all the methods are in the Tickers module.
The download module is for quickly downloading the historical information of multiple tickers at one time.
And pandas_datareader is for dorsum compatibility with legacy code, which we will ignore as irrelevant since if you're reading this yous are probably a new user of the library!
How exercise I download historical data using the yfinance library?
Demo with one ticker
Firstly, lets import yfinance equally yf and create ourselves a ticker object for a particular ticker (stock):
import yfinance equally yf aapl= yf.Ticker("aapl") aapl yfinance.Ticker object <AAPL> Remember we now use this aapl ticker object for almost everything- calling various methods on it.
To get the historical data we want to use the history() method, which is the almost "complicated" method in the yfinance library.
It takes the following parameters equally input:
- period: information menses to download (either use menstruation parameter or use kickoff and finish) Valid periods are:
- "1d", "5d", "1mo", "3mo", "6mo", "1y", "2y", "5y", "10y", "ytd", "max"
- interval: data interval (1m data is only for available for concluding 7 days, and data interval <1d for the final 60 days) Valid intervals are:
- "1m", "2m", "5m", "15m", "30m", "60m", "90m", "1h", "1d", "5d", "1wk", "1mo", "3mo"
- start: If not using flow – in the format (yyyy-mm-dd) or datetime.
- cease: If not using period – in the format (yyyy-mm-dd) or datetime.
- prepost: Include Pre and Mail service regular market data in results? (Default is
Faux)- no need commonly to change this from False - auto_adjust: Adjust all OHLC (Open/High/Low/Close prices) automatically? (Default is
True)- simply leave this always as true and don't worry about it - actions: Download stock dividends and stock splits events? (Default is
True)
That might expect a piddling complex only mainly you lot will but exist changing the menses (or showtime and end) and interval parameters.
So as an case, to become 1minute historical data for Apple between 02/06/2020 and 07/06/2020 (British format) nosotros just use the ticker object nosotros created and run:
aapl_historical = aapl.history(kickoff="2020-06-02", end="2020-06-07", interval="1m") aapl_historical 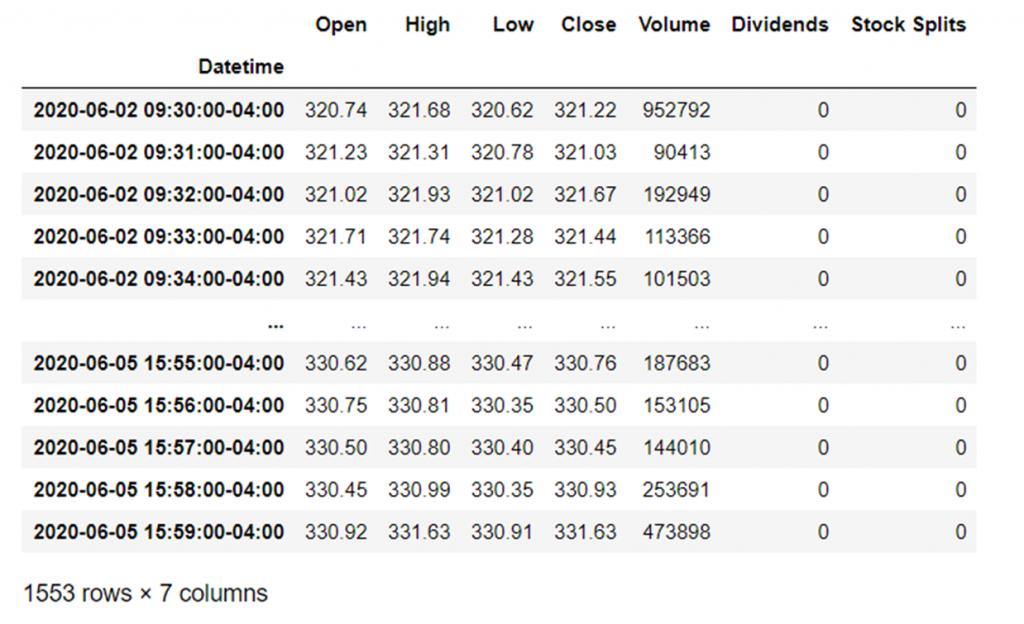
It's as simple as that!
Demo with multiple tickers
To download the historical data for multiple tickers at one time you tin use the download module.
It takes generally the same arguments as the history() method on a ticker object, just additionally:
- group_by: grouping past cavalcade or ticker ('column'/'ticker', default is 'column')
- threads: apply threads for mass downloading? (True/False/Integer)
- proxy: proxy URL if you want to utilise a proxy server for downloading the information (optional, default is None)
For example to get the information for Amazon, Apple and Google all at one time we tin run:
data = yf.download("AMZN AAPL GOOG", start="2017-01-01", terminate="2017-04-30") information 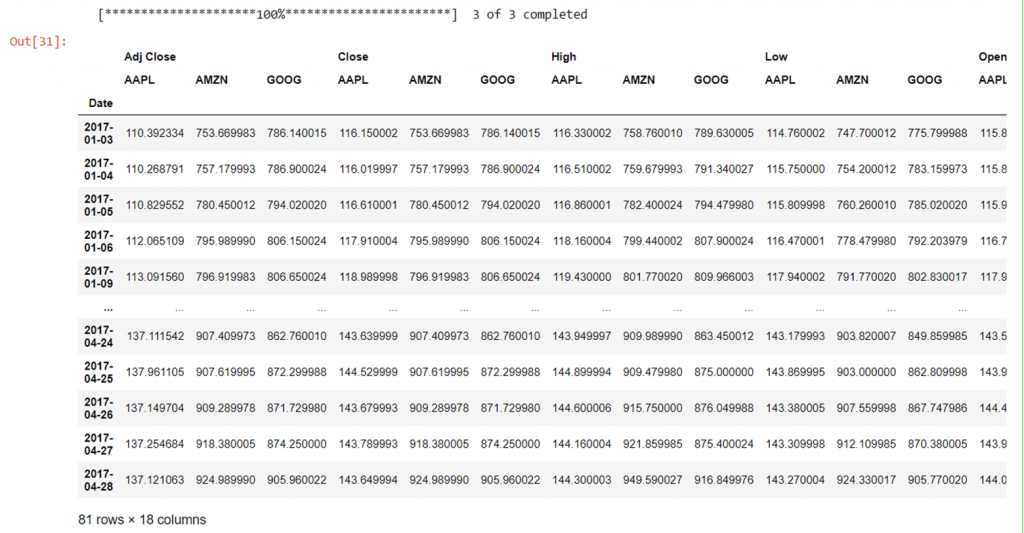
Annotation that the default with no interval specified is daily data.
Then, if we want to grouping past ticker instead of Open/High/Low/Shut we tin practise:
data = yf.download("AMZN AAPL GOOG", outset="2017-01-01", finish="2017-04-30", group_by='tickers') data 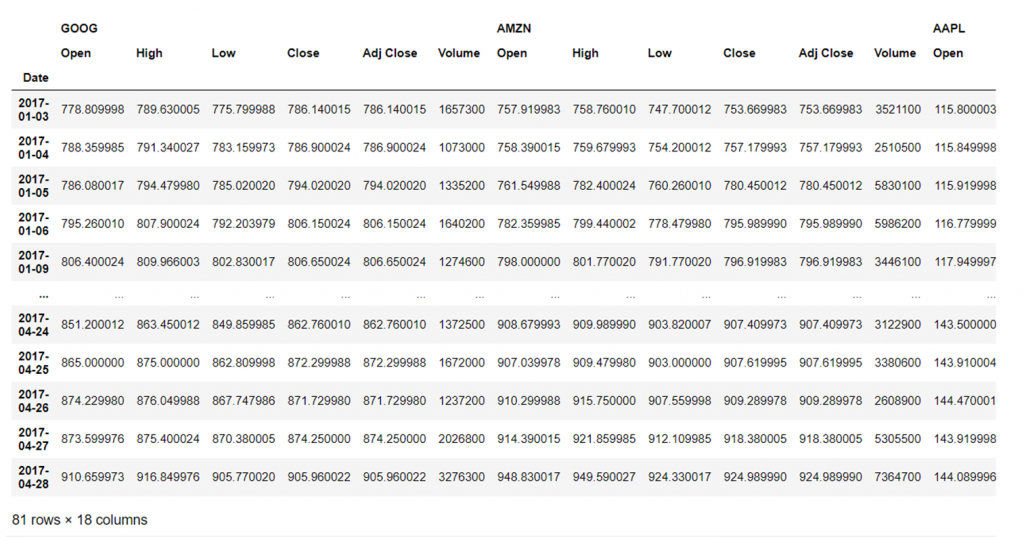
How practise I download key data using the yfinance library?
Price to Earnings Ratio
You can get the toll to earnings ratio with the Ticker.info() method.
Ticker.info() returns a dictionary with a broad range of information virtually a ticker, including such things as a summary clarification, employee count, marketcap, volume, P/E ratios, dividends etc.- we recommend taking a wait at it yourself as it takes a lot of infinite to evidence, but in short if yous can't find the information you're looking for with the other methods, attempt the info() method!
To get specifically the cost to earnings ratio search the dictionary for 'forwardPE':
aapl = yf.Ticker("aapl") aapl.info['forwardPE'] 22.799461 Dividends
Yous can get the yearly dividend % also by using info():
aapl.info['dividendRate'] 3.2800000000000002 And if yous want a breakup of each dividend payout as it occurred and on what date, yous can utilise Ticker.dividends():
Appointment 1987-05-11 0.00214 1987-08-10 0.00214 1987-11-17 0.00286 1988-02-12 0.00286 1988-05-16 0.00286 ... 2019-05-10 0.77000 2019-08-09 0.77000 2019-xi-07 0.77000 2020-02-07 0.77000 2020-05-08 0.82000 Name: Dividends, Length: 67, dtype: float64 Fundamentals data with multiple tickers at in one case
We might also want to take hold of fundamentals (or other) data for a bunch of tickers at once.
Lets have a go at doing that and then try comparing our tickers by a particular aspect!
To do this nosotros tin start by creating a list of the tickers nosotros desire to get information for, and an empty dictionary to store all the data.
Nosotros will need to use the pandas library to dispense the information frames:
import pandas every bit pd tickers_list = ["aapl", "goog", "amzn", "BAC", "BA"] # example listing tickers_data= {} # empty dictionary We and then loop through the list of the tickers, in each case adding to our dictionary a key, value pair where the key is the ticker and the value the dataframe returned by the info() method for that ticker:
for ticker in tickers_list: ticker_object = yf.Ticker(ticker) #catechumen info() output from dictionary to dataframe temp = pd.DataFrame.from_dict(ticker_object.info, orient="index") temp.reset_index(inplace=Truthful) temp.columns = ["Attribute", "Contempo"] # add (ticker, dataframe) to main dictionary tickers_data[ticker] = temp tickers_data 
Nosotros then combine this dictionary of dataframes into a single dataframe:
combined_data = pd.concat(tickers_data) combined_data = combined_data.reset_index() combined_data 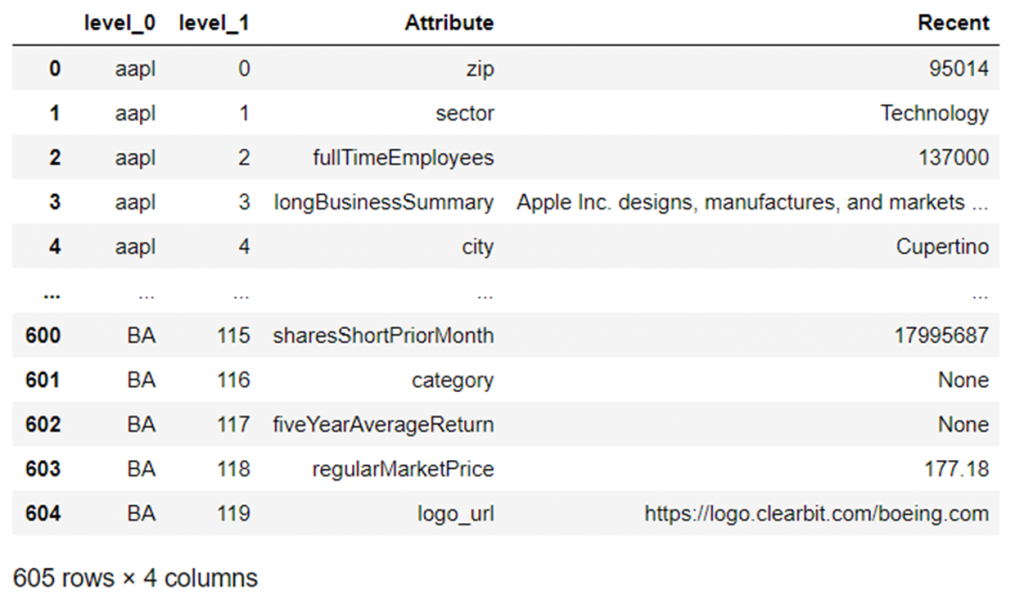
And then delete the unnecessary "level_1" cavalcade and make clean up the column names:
del combined_data["level_1"] # make clean up unnecessary column combined_data.columns = ["Ticker", "Aspect", "Contempo"] # update column names combined_data 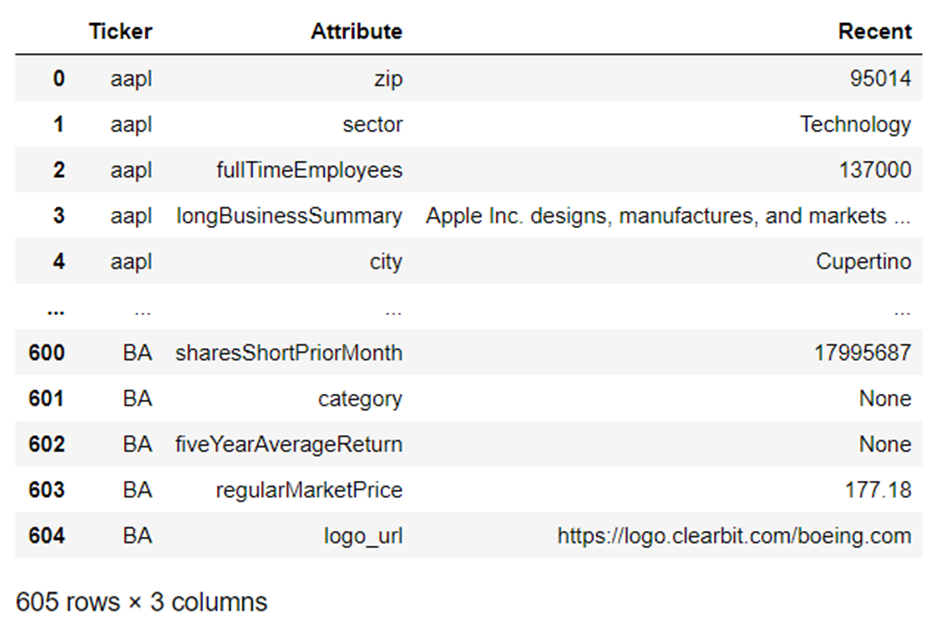
Great, so we at present know how to get whatsoever data we want for multiple tickers at one time into the same dataframe!
Simply how practice nosotros easily compare by a particular aspect?
Comparing by a particular aspect
It'southward quite easy actually, lets try for i of the attributes in info()– the fullTimeEmployees count:
employees = combined_data[combined_data["Aspect"]=="fullTimeEmployees"].reset_index() del employees["alphabetize"] # make clean up unnecessary column employees 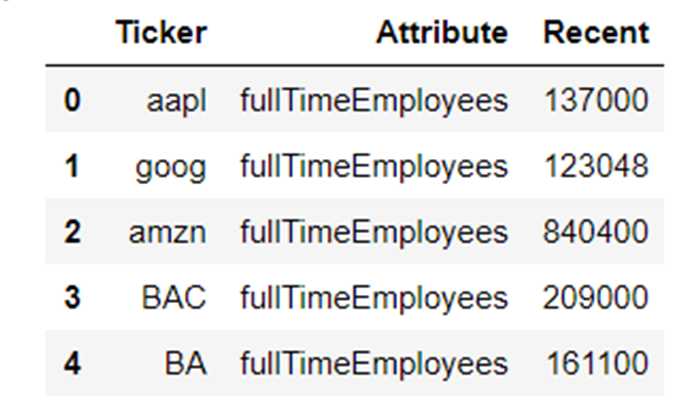
So at present nosotros take a dataframe of just the employee counts- one entry per ticker- and we can at present gild by the 'Recent' column:
employees_sorted = employees.sort_values('Recent',ascending=Imitation) employees_sorted 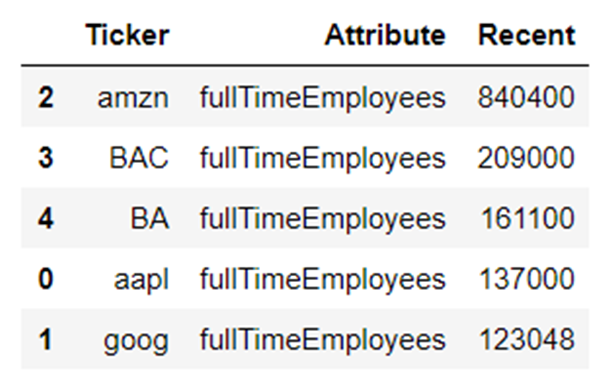
Boom! Obviously not that required with only 5 tickers in our list, only a fantastically easy and powerful way to quickly compare past a particular aspect if we had the ticker list of an unabridged market!
You tin easily employ this verbal same method to compare any attribute y'all desire!
How do I download trading data using the yfinance library?
You tin find the data for all three of Market Cap, Volume and Highs and Lows from the info() method.
Marketplace Cap
To become the market cap, apply:
1525510701056 Book
To find the current volume do:
8021292 If you desire the average volume over the concluding 24 hours do:
aapl.info["averageVolume"] 42532806 And finally if you want the average volume over the concluding 10 days:
aapl.info["averageVolume10days"] 39594100 Highs and Lows
Retrieve, y'all tin find the highs and lows for whatever time interval:
- "1m", "2m", "5m", "15m", "30m", "60m", "90m", "1h", "1d", "5d", "1wk", "1mo", "3mo"
within a desired menstruation by using the history() method and adjusting the interval.
For example, to get the weekly highs and lows for all the historical data that exists, utilize:
aapl_historical = aapl.history(menstruum="max", interval="1wk") aapl_historical 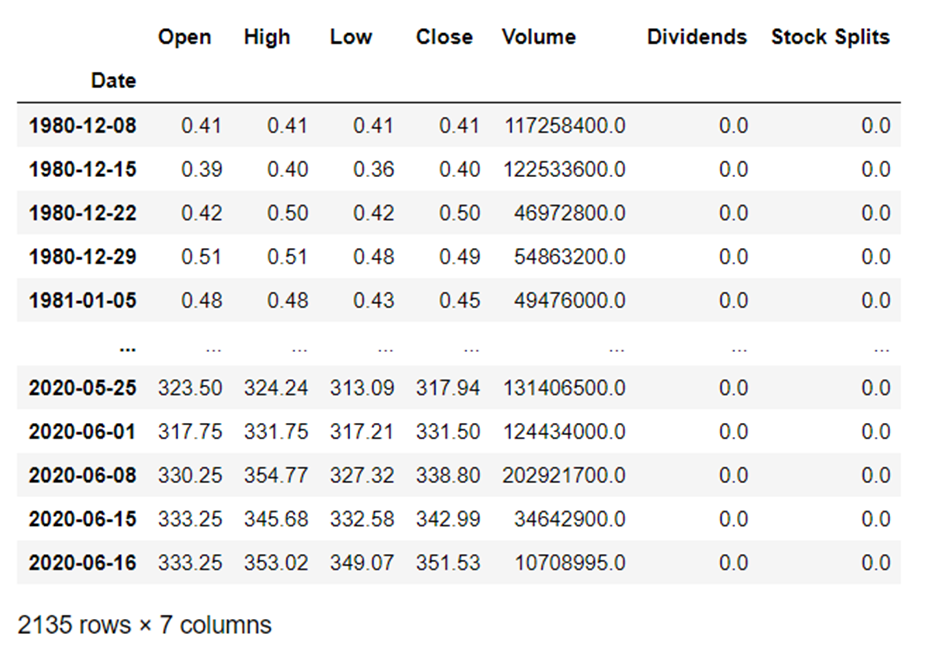
Wow, almost 40 years of information!
Just filter the dataframe with:
- aapl_historical["High"]
- aapl_historical["Low"]
And then forth to become the individual columns.
Alternatively, you lot can utilise info() to become the following useful high/low information:
- dayHigh
- dayLow
- fiftyTwoWeekHigh
- fiftyTwoWeekLow
For instance:
aapl.info["fiftyTwoWeekHigh"] 354.77 How do I download options data using the yfinance library?
Briefly, options are contracts giving a trader the right, but non theobligation, to buy (telephone call) or sell (put) the underlying asset they represent at a specific toll on or before a certain appointment.
To download options data we can use the option_chain() method. It takes the parameter equally input:
- date: (YYYY-MM-DD), decease date. If None render all options data.
And has the opt.calls and opt.puts methods.
How practise I get Expiration dates?
To get the various expiry dates for options for a particular ticker it'due south as easy as:
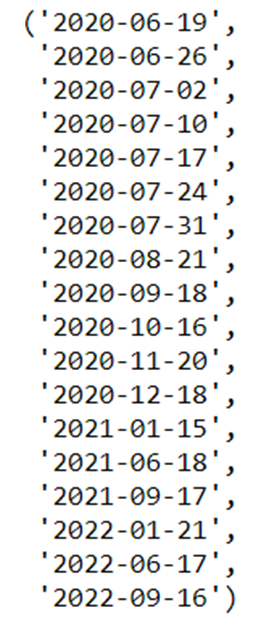
How do I get Calls Data?
To get the calls data, nosotros tin can practice:
# get pick chain calls data for specific expiration date opt = aapl.option_chain(appointment='2020-07-24') opt.calls 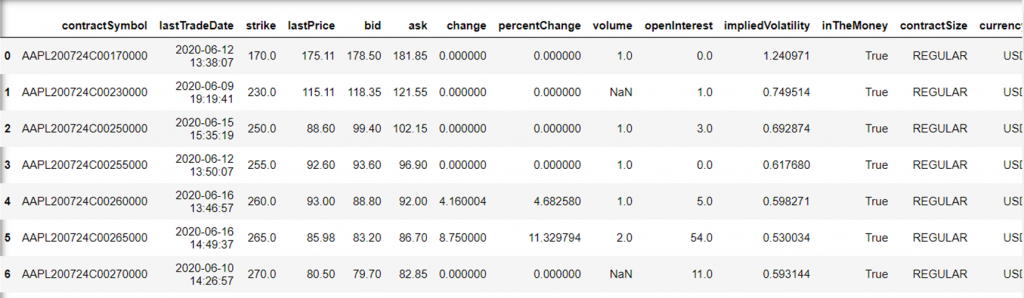
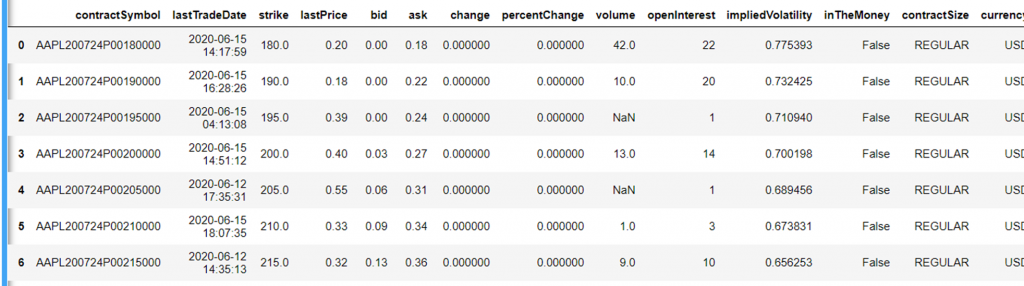
How practice I get Puts Data?
To get puts information, we do:
Finally, opts by itself returns a ticker object containing both the calls and puts information together, if that's useful to you!
Mutual errors
Equally we highlighted nearly the beginning of this article, yfinance is an unofficial scraping solution to gather data from Yahoo Finance, so is subject field to breaking if Yahoo Finance changes whatsoever of its layout.
Unfortunately this already seems to accept happened in part, with the post-obit problems discovered when writing this guide:
- Tickers, the multiple tickers object for interacting with multiple tickers at once, doesn't seem to piece of work. We have provided a more than manual workaround for this in the Fundamentals data with multiple tickers at once department.
- The financials, quarterly_financials, balance_sheet, quarterly_balance_sheet, cashflow, quarterly_cashflow, earnings, quarterly_earnings Ticker methods practice not piece of work and return empty dataframes.
This is a big problem equally in many cases in that location is no alternative way to the data in some of these methods from other methods in yfinance.
If you are building something that requires any of this information, for instance balance sheets and income and cashflow statements and still desire free access to the Yahoo Finance data, check out the yahoo_fin library in the examples department of our guide https://algotrading101.com/acquire/yahoo-finance-api/ which has working methods to become all of this information!
Final thoughts
So conspicuously every bit nosotros have merely demonstrated, yfinance is NOT a prophylactic bet to build critical infrastructure on.
If you want to build algorithms trading real coin, we absolutely recommend y'all use an official data source/API, preferably ane connected direct to commutation data and with low latency. Something like Polygon.io or IEX might suit you meliorate.
If you absolutely Have to use the Yahoo Finance data specifically, we recommend at to the lowest degree paying for an unofficial API similar RapidAPI, where you stand a good bet there is an agile squad of developers constantly maintaining the API. Retrieve RapidAPI does withal have a express usage gratuitous tier!
That said, yfinance can be good to use to build test applications as a beginner, as the sections of information technology that exercise work are fantastically easy to become started with and use.
A particular forte of yfinance is that the threads parameter of yf.download does allow very rapid downloading of historical for multiple tickers when gear up to True!
Link to download code used
You lot can find the code used in this article here.
Source: https://algotrading101.com/learn/yfinance-guide/
0 Response to "Can I Change Binance to Read in Usd Only"
Post a Comment