Reading and Not Reading â€å“the Man of the Crowdã¢â‚¬â: Poe, the City, and the Gothic Text Summarizer
Table of Contents
- Introduction to Text Summarization
- Difficulties of Text Summarization
- Architecture Overview
- Problem Statement
- Installation Requirements
- Data - Implementation
- Load Text
- Clean Text
- Create Network
- Generate Summary - Concluding Remarks
- Resources
Introduction to Text Summarization
In modern social club, with the demand to ingest data in a rapid format, text summarization is an essential tool used by many on a daily ground. With up prominent get-go ups like Blinkist which provide short detailed summaries of a large corpus of books. This saves their users hours if not days of reading. Many other companies also apply their proprietary text summarization software to salve their users time. Other forms of summarizations (admitting in a dissimilar medium) comes in the forms of highlight reels of sports events or flick recaps.
There a re ii main approaches of text summarization, namely, extractive and abstractive. The extractive solutions requires selecting specific sentences from the body of text to generate the final summary. The full general arroyo to extractive solutions are associated to ranking sentences on their importance in the torso of text and returning the well-nigh important sentences back to the user. Yet, abstractive solutions to text summarization involves creating new sentences to capture context and meaning behind the original body of text. Although this is how humans approach text summarization, it's quite a difficult thing to generalize and teach to a machine. Text compression techniques are usually used to solve abstractive approaches in text summarization [four].
In this article I will show you lot how to build an algorithmic text summarizer using the extractive approach. I will rely on two chief algorithms, firstly, the Jaro-Winkler distance to mensurate the distance between a pair of sentences. Lastly, the page rank algorithm, which volition rank the sentences based on their influence in the network.
Difficulties of Text Summarization
To solve summarization problems are quite tricky. In that location are a lot of caveats and it is quite difficult to generalize a solution to work for whatsoever body of text. In that location are various factors in text summarization which changes the impact the summary might have on the original story. I've outlined a few components below which makes summarization a very hard task in NLP:
- What is the ideal number of sentences that the summary must hold? A number too large might exist useless since you're practically reading the entire torso of text. A number too small might accept large consequences in the summary, skipping over important details and plot lines. The shorter the summary, the less information it tin hold.
- How tin can you requite context in the summary? When providing summaries of subplots within the story the context is the most of import part. Information technology's what makes the summary useful, keeping context in the summary is a very difficult task. This problem is more prominent in extractive solutions than abstractive.
Architecture Overview
The extractive solution I'thousand proposing will have the following architecture:
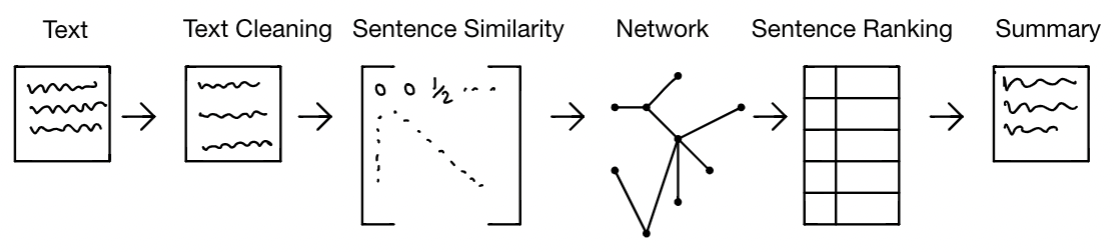
It will be a half dozen footstep solution:
- Become the input text
- Make clean the input text of sure punctuations, stopwords, etc.
- Generate a sentence similarity adjacency matrix
- Create the sentence network (nodes are sentences and edges hold the similarity of a pair of sentences)
- Rank the nodes in the network using page rank or other ranking measures
- Generate the summary based on the acme N ranked nodes (sentences).
Problem Argument
Given a body of text we volition create a pipeline which will generate a summary of the input trunk of text. For the approach to solving this problem which was outlined to a higher place, this pipeline requires the following python modules and versions.
Installation Requirements
Python=3.8.8
jaro-winkler=2.0.1
networkx=2.5
nltk=3.6.1
numpy=1.twenty.1 To install the Jaro bundle through the following command !pip install jaro-winkler or you tin reference the installation documentation here.
Data
I've set up this tutorial in a manner that any torso of text can be input to the pipeline. Go along on with this tutorial with the text I've selected or utilize your ain. Below are a ready of books you can easily download through the NLTK library and Gutenberg project. All of these books are free to use every bit they are a office of the public domain.
For the purposes of this tutorial, I will be using Shakespeare's play on Julius Caesar. Do note that this and all other bodies of text written by William Shakespeare is in the public domain, as the bodies of text were created prior to the being of any copyright restrictions [2].
Implementation
Load Text
Below is a sample output of how the volume variable looks:

Make clean Text
In this section we're going to make clean up the text we've just imported. For this we are primarily going to remove stopwords and certain punctuations and then the procedures after on in the pipeline can exist more efficient and accurate in their calculation.
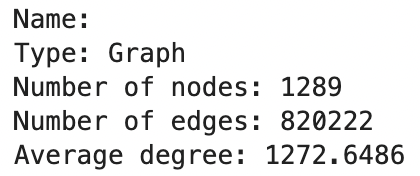
After cleaning up the body of text, we're left with 1289 sentences to create a network from.
Create Network
In this section we will create an adjacency matrix through the similarity of various sentences. The similarity of sentences will be calculated using the Jaro-Winkler altitude [iii]. The output of this distance measure will exist a floating point number betwixt the values of 0 and 1. The closer this number is to ane indicates the more similar the pair of sentences are. The closer the number is to 0 indicates the more the pair of sentences are not similar.
This adjacency matrix will then permit us to create a weighted network (through NetworkX). Please keep in listen the size of your input trunk of text, since the similarity matrix needs to assign a score for each pair of sentences it will exist an extensive and exhausting process for your computer if your torso of text is very large (> 2000 sentences).
In the created network, the nodes will be indices associated to the sentences in the book and the edges connecting the sentences will be weighted based on the similarity of a pair of sentences. We tin can then run the page rank algorithm on that weighted network to identify nodes with a large rank associated to them.
At very high level, the intuition behind the folio rank algorithm is to identify highly pop nodes through the use of random walks. It's a very popular network based algorithm Larry Folio and was famously used past Google to rank their web pages in their search engine results [1]. In the context of our example, page rank will tell u.s.a. highly influential sentences in the network. We can and so take the top N near influential sentences, bring together them together and render them dorsum to the user in the form of a summary of the original body of text. Do notation that at that place are many ways to rank a node, although page rank is the i I'm proposing nosotros use, ranking measures like eigenvector axis, caste centrality, betweenness axis and others are also valid for the purposes of this pipeline.
It took ~2 minutes to create the similarity matrix given 1289 sentences. The creation of the network and calculation of the page rank scores were nigh instantaneous. The following is a summary of the created network :
The built in page rank office will output a dictionary where the keys are the nodes (sentence index in our case) and the values are the associated folio rank score to that node.

Exercise keep in mind that we want to map the sentence index back to the original sentence and non the cleaned one used to create the network. This way, the resulting summary generated will exist much easier to interpret when including the cease words, punctuations, etc.
Generate Summary
Now that we have ranked the sentences based on their page rank score, we tin can generate a summary given the users input number of sentences they want in the summary.
For the purposes of this article, I chose 25 sentences to exist the number of sentences to summarize this body of text. This was the associated output:

Concluding Remarks
The effect of the summary would vary from text to text, certain bodies of text might exist improve than others for the given chore. Overall, the summary outlined in this pipeline for Julius Caesar wasn't too poor. It outlines the primary plot line that Brutus (Caesar'southward friend) was trying to electrocute Caesar.
You can discover the Jupyter Notebook associated to the implementation of this pipeline in my GitHub hither.
Resources
- [1] https://en.wikipedia.org/wiki/PageRank
- [2] https://en.wikipedia.org/wiki/Public_domain
- [3] https://en.wikipedia.org/wiki/Jaro%E2%80%93Winkler_distance
- [4] https://arxiv.org/pdf/1707.02268.pdf
Source: https://towardsdatascience.com/text-summarization-in-python-with-jaro-winkler-and-pagerank-72d693da94e8
0 Response to "Reading and Not Reading â€å“the Man of the Crowdã¢â‚¬â: Poe, the City, and the Gothic Text Summarizer"
Post a Comment